
DDRS documentation
The DDRS (Data Deposit Recommendation Service) is an outcome of the Humanities at Scale project Work Package 7.
![]()
Use cases
The following section describe the most relevant use cases for the DDRS. By describing the use cases in a structured way, we try to cover all necessary aspects that should be considered with the design of the service.
Researcher driven use cases
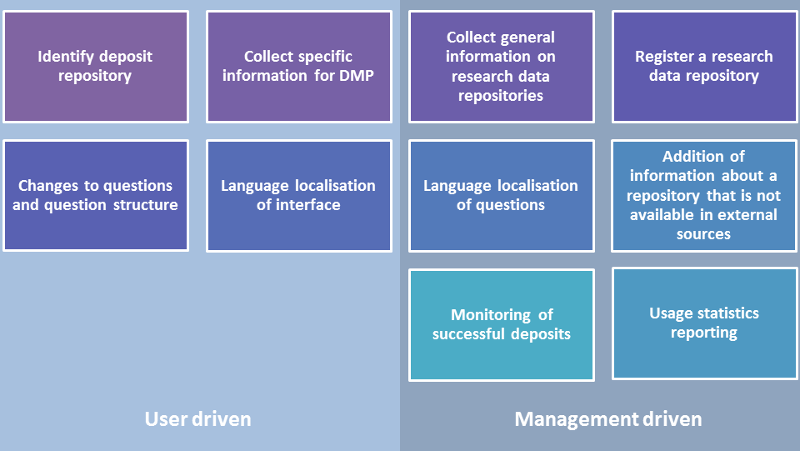
The DDRS offers benefit for at least the following four basic researcher driven use scenarios and six management driven use cases (refer also to the figure below):
- (A) Identify deposit repositories: the user - a scholar or a researcher - wants to archive a set of research data and has to identify a suitable repository which should fulfill certain requirements. These requirements can be deducted from the research funder’s policy or be set by the user himself and will be fixed through a questionnaire process. The questionnaire should be as short as possible, requiring maybe not more than five questions. The DDRS should be not only able to suggest the best suited repository, or a list of ranked repositories, but also be able to initiate the contact between the user and repository/-ies. One desirable feature of the DDRS would be to build up a growing memory of “requests/decisions” to improve or accelerate the identification process.
- (B) Collect specific information for a DMP: the user - a scholar or researcher - has to collect information for a project specific data management plan. The necessary information comprises - amongst other things - information on the deposit repository and some of its specifications such as access policy or discipline coverage. The process for collecting this kind of information could basically be the same as the above described one for the identification of research data repositories.
- (C) Collect general information on research data repositories: the user wants to inform himself on the research data repository landscape. This information interest can be focussed on disciplines, access policies or can be country- or language-specific. The DDRS should offer for this use case a transparent, complete and detailed browsing option to perform different searches in a row. This could be implemented similarly to the re3data-interface but with lesser categories.
- (D) Register a research data repository: the user - a repository operator - wants to register his service for the DDRS. This should be conveniently possible directly via the DDRS or - if we pursue the intended plan - via re3data. This use case is aimed at extending the visibility of research data repositories and/or enhancing the database quality and quantity of re3data. The DDRS could be a leverage for repositories to improve their dissemination and interoperability.
Management driven use cases
Furthermore, the DDRS system has six management use cases (refer also to figure 4):
- (F) Language localisation of interface: the service has to be designed in a way that future localisations can be incorporated as easy as possible. This demand is important for the usability of the services.
- (G) Addition of information about a repository that is not available in external sources: as in the current design state the service relies heavily on the re3data-database to identify suitable repositories for the user. As this database does not focus on the arts and humanities we have a likely risk of non-inclusion of repositories that may be relevant for the user. The gap of these “missing repositories” can be addressed at least in two ways: indexing them in the re3data-database or adding the information on the side of the DDRS. Although the latter way seems more challenging it opens the way for including other information than those included in the re3data-database. As a reminder, the re3data-database relies upon a selected set of properties summarised in the re3data-metadata schema v.2.2. This schema covers all research domains and is not arts and humanities-specific. A new version of the schema is being implemented within the re3data API, version 3.0.
- (H) Monitoring of successful deposits: this aspect relates to the above described usage statistics. The data on successful deposits would be a main quality indicator for the DDRS. So far the design approach does not offer an easy implementation for the monitoring of successful deposits. If a deposit is finished successfully the user will not return this result to the DDRS. Possibly this aspect can be covered during the forwarding of the ingest request to the repository. Simply spoken: the form includes our request to receive an update on a successful ingest, as some kind of brokerage fee.
- (I) Usage statistics reporting: the DDRS has to include some kind of usage statistics reporting. This is not only important to improve the quality internally but it becomes crucial with regard to two aspects: firstly it becomes possible to use the usage statistics as an enrichment for the identification process, i.e. to rank services along their popularity; secondly the usage statistics can be used to raise the attractiveness of the service towards repositories that so have not been included both in our DDRS or in re3data.
- (J) Changes to questions and question structure: the design of the service has to reflect a flexibility to change the set of questions in the future. This can become necessary as soon as the used database changes, e.g. gets more granular in certain areas, or as the users’ perceptions of research data changes, e.g. new issues become important for them or other issues are becoming less important. This flexibility is necessary both for the questions used to identify repositories for the user but also for the data description process. Likely the latter one is more easy to adapt than the questionnaire process.
- (K) Language localisation of questions: the service has to be designed in a way that future localisations can be incorporated as easy as possible. This demand is important for the usability of the services.